
Isi
- Klub Skeptis
- Jaringan Neural Konvolusional (CNN)
- Tanpa Bug, Tanpa Stres - Panduan Langkah Demi Langkah Anda untuk Membuat Perangkat Lunak yang Mengubah Hidup Tanpa Menghancurkan Kehidupan Anda
- Unit Memori Jangka Pendek (LSTM) Panjang
- Generative Adversarial Networks (GAN)
- Kesimpulan

Sumber: Vs1489 / Dreamstime.com
Bawa pulang:
Apakah "pembelajaran mendalam" hanyalah nama lain untuk jaringan saraf canggih, atau adakah lebih dari itu? Kami melihat kemajuan terbaru dalam pembelajaran mendalam serta jaringan saraf.
Klub Skeptis
Jika Anda, seperti saya, adalah anggota klub skeptis, Anda juga mungkin bertanya-tanya apa yang sedang terjadi dalam pembelajaran mendalam. Jaringan saraf (NNs) bukan konsep baru. Perceptron multilayer diperkenalkan pada tahun 1961, yang tidak persis baru kemarin.
Tetapi jaringan saraf saat ini lebih kompleks dari sekedar perceptron multilayer; mereka dapat memiliki lebih banyak lapisan tersembunyi dan bahkan koneksi berulang. Tapi tunggu dulu, bukankah mereka masih menggunakan algoritma backpropagation untuk pelatihan?
Iya! Sekarang, daya komputasi alat berat tidak dapat dibandingkan dengan apa yang tersedia di tahun 60-an atau bahkan di tahun 80-an. Ini berarti arsitektur saraf yang jauh lebih kompleks dapat dilatih dalam waktu yang wajar.
Jadi, jika konsepnya tidak baru, dapatkah ini berarti bahwa pembelajaran yang mendalam hanyalah sekelompok jaringan saraf pada steroid? Apakah semua keributan hanya karena komputasi paralel dan mesin yang lebih kuat? Seringkali, ketika saya memeriksa apa yang disebut solusi pembelajaran mendalam, seperti inilah kelihatannya. (Apa sajakah praktis, penggunaan dunia nyata untuk jaringan saraf? Cari tahu di 5 Kasus Penggunaan Jaringan Neural yang Akan Membantu Anda Memahami Teknologi Lebih Baik.)
Seperti yang saya katakan, saya termasuk dalam klub skeptis, dan saya biasanya waspada terhadap bukti yang belum didukung. Untuk sekali ini, mari kita singkirkan prasangka, dan mari kita coba penyelidikan menyeluruh dari teknik-teknik baru yang muncul dalam pembelajaran mendalam sehubungan dengan jaringan saraf, jika ada.
Ketika menggali sedikit lebih dalam, kami menemukan beberapa unit, arsitektur, dan teknik baru di bidang pembelajaran mendalam. Beberapa inovasi ini memiliki bobot yang lebih kecil, seperti pengacakan yang diperkenalkan oleh lapisan putus sekolah. Namun, beberapa yang lain bertanggung jawab atas perubahan yang lebih penting. Dan, tentu saja, sebagian besar dari mereka bergantung pada ketersediaan sumber daya komputasi yang lebih besar karena mereka cukup mahal secara komputasi.
Menurut pendapat saya, ada tiga inovasi utama di bidang jaringan saraf yang telah memberikan kontribusi besar bagi pembelajaran mendalam untuk mendapatkan popularitasnya saat ini: jaringan saraf convolutional (CNNs), unit memori jangka pendek (LSTM) jangka panjang dan jaringan permusuhan generatif (GAN) ).
Jaringan Neural Konvolusional (CNN)
Ledakan besar pembelajaran mendalam - atau setidaknya ketika saya mendengar booming untuk pertama kalinya - terjadi dalam proyek pengenalan gambar, Tantangan Pengenalan Visual Skala Besar ImageNet, pada tahun 2012. Untuk mengenali gambar secara otomatis, jaringan saraf convolutional dengan delapan lapisan - AlexNet - digunakan. Lima lapisan pertama adalah lapisan convolutional, beberapa dari mereka diikuti oleh lapisan max-pooling, dan tiga lapisan terakhir adalah lapisan yang sepenuhnya terhubung, semua dengan fungsi aktivasi ReLU yang tidak jenuh. Jaringan AlexNet mencapai kesalahan lima besar sebesar 15,3%, lebih dari 10,8 poin persentase lebih rendah dari pada peringkat kedua. Itu adalah prestasi luar biasa!
Tanpa Bug, Tanpa Stres - Panduan Langkah Demi Langkah Anda untuk Membuat Perangkat Lunak yang Mengubah Hidup Tanpa Menghancurkan Kehidupan Anda

Anda tidak dapat meningkatkan keterampilan pemrograman Anda ketika tidak ada yang peduli dengan kualitas perangkat lunak.
Selain arsitektur multilayer, inovasi terbesar AlexNet adalah lapisan convolutional.
Lapisan pertama dalam jaringan convolutional selalu merupakan lapisan convolutional. Setiap neuron dalam lapisan konvolusional berfokus pada area spesifik (bidang reseptif) dari gambar input dan melalui koneksi tertimbangnya bertindak sebagai filter untuk bidang reseptif. Setelah menggeser filter, neuron demi neuron, di atas semua bidang reseptif gambar, output dari lapisan konvolusional menghasilkan peta aktivasi atau peta fitur, yang dapat digunakan sebagai pengidentifikasi fitur.
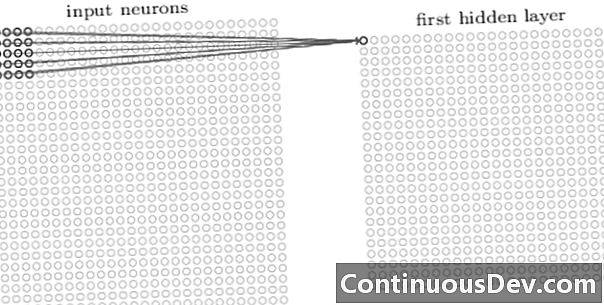
Dengan menambahkan lebih banyak lapisan konvolusional di atas satu sama lain, peta aktivasi dapat mewakili fitur yang lebih dan lebih kompleks dari gambar input. Selain itu, sering dalam arsitektur jaringan saraf convolutional, beberapa lapisan lagi diselingi antara semua lapisan konvolusional ini untuk meningkatkan nonlinieritas fungsi pemetaan, meningkatkan kekokohan jaringan dan mengontrol overfitting.
Sekarang kita dapat mendeteksi fitur tingkat tinggi dari gambar input, kita dapat menambahkan satu atau lebih lapisan yang terhubung sepenuhnya ke ujung jaringan untuk klasifikasi tradisional. Bagian terakhir dari jaringan ini mengambil output dari lapisan convolutional sebagai input dan output vektor N-dimensi, di mana N adalah jumlah kelas. Setiap angka dalam vektor dimensi-N ini mewakili probabilitas suatu kelas.
Kembali pada hari itu, saya sering mendengar keberatan terhadap jaringan saraf tentang kurangnya transparansi arsitektur mereka dan ketidakmungkinan untuk menafsirkan dan menjelaskan hasilnya. Keberatan ini semakin jarang muncul saat ini sehubungan dengan jaringan pembelajaran yang mendalam. Tampaknya sekarang dapat diterima untuk memperdagangkan efek kotak hitam untuk akurasi klasifikasi yang lebih tinggi.
Unit Memori Jangka Pendek (LSTM) Panjang
Peningkatan besar lainnya yang dihasilkan oleh jaringan saraf pembelajaran dalam telah terlihat dalam analisis deret waktu melalui jaringan saraf berulang (RNNs).
Jaringan saraf berulang bukan konsep baru. Mereka sudah digunakan di tahun 90-an dan dilatih dengan algoritma backpropagation through time (BPTT). Namun di tahun 90-an, seringkali tidak mungkin untuk melatih mereka mengingat jumlah sumber daya komputasi yang diperlukan. Namun, saat ini, karena peningkatan daya komputasi yang tersedia, menjadi tidak hanya mungkin untuk melatih RNN tetapi juga untuk meningkatkan kompleksitas arsitektur mereka. Apakah itu semuanya? Ya tentu saja tidak.
Pada tahun 1997, sebuah unit saraf khusus diperkenalkan untuk menangani lebih baik dengan menghafal masa lalu yang relevan dalam serangkaian waktu: unit LSTM. Melalui kombinasi gerbang internal, unit LSTM mampu mengingat informasi masa lalu yang relevan atau melupakan konten masa lalu yang tidak relevan dalam rangkaian waktu. Jaringan LSTM adalah jenis khusus dari jaringan saraf berulang, termasuk unit LSTM. Versi terbuka dari RNN berbasis LSTM ditunjukkan pada Gambar 2.
Untuk mengatasi masalah kemampuan memori panjang yang terbatas, unit LSTM menggunakan status tersembunyi tambahan - status sel C (t) - berasal dari keadaan tersembunyi asli h (t). C (t) mewakili memori jaringan. Struktur tertentu, yang disebut gerbang, memungkinkan Anda untuk menghapus (lupa) atau menambahkan (ingat) informasi ke keadaan sel C (t) pada setiap langkah waktu berdasarkan pada nilai input x (t) dan kondisi tersembunyi sebelumnya h (t − 1). Setiap gerbang memutuskan informasi mana yang akan ditambahkan atau dihapus dengan mengeluarkan nilai antara 0 dan 1. Dengan mengalikan keluaran gerbang secara langsung dengan keadaan sel C (t − 1), informasi dihapus (keluaran gerbang = 0) atau disimpan (keluaran gerbang = 1).
Pada Gambar 2, kita melihat struktur jaringan unit LSTM. Setiap unit LSTM memiliki tiga gerbang. "Lupa gerbang lapisan" di awal menyaring informasi dari keadaan sel sebelumnya C (t − 1) berdasarkan input saat ini x (t) dan status tersembunyi sel sebelumnya h (t − 1). Selanjutnya, kombinasi "lapisan gerbang input" dan "lapisan tanh" memutuskan informasi mana yang akan ditambahkan ke keadaan sel sebelumnya, yang sudah difilter, C (t − 1). Akhirnya, gerbang terakhir, "gerbang keluaran," memutuskan mana dari informasi dari keadaan sel yang diperbarui C (t) berakhir di keadaan tersembunyi berikutnya h (t).
Untuk detail lebih lanjut tentang unit LSTM, lihat posting blog GitHub "Memahami Jaringan LSTM" oleh Christopher Olah.
Gambar 2. Struktur sel LSTM (direproduksi dari "Deep Learning" oleh Ian Goodfellow, Yoshua Bengio dan Aaron Courville). Perhatikan tiga gerbang di dalam unit LSTM. Dari kiri ke kanan: gerbang lupa, gerbang input, dan gerbang keluaran.
Unit LSTM telah berhasil digunakan dalam sejumlah masalah prediksi deret waktu, tetapi terutama dalam pengenalan ucapan, pemrosesan bahasa alami (NLP), dan pembangkitan bebas.
Generative Adversarial Networks (GAN)

Jaringan permusuhan generatif (GAN) terdiri dari dua jaringan pembelajaran yang dalam, generator dan pembeda.
Generator G adalah transformasi yang mengubah kebisingan input z menjadi tensor - biasanya sebuah gambar - x (x= G (z)). DCGAN adalah salah satu desain paling populer untuk jaringan generator. Dalam jaringan CycleGAN, generator melakukan beberapa konvolusi yang dialihkan ke upample z untuk akhirnya menghasilkan gambar x (Gambar 3).
Gambar yang dihasilkan x kemudian dimasukkan ke dalam jaringan diskriminator. Jaringan diskriminator memeriksa gambar nyata dalam set pelatihan dan gambar yang dihasilkan oleh jaringan generator dan menghasilkan output D (x), Yang merupakan probabilitas gambar itu x adalah nyata.
Baik generator dan diskriminator dilatih menggunakan algoritma backpropagation untuk menghasilkan D (x)=1 untuk gambar yang dihasilkan. Kedua jaringan dilatih dalam langkah bergantian bersaing untuk meningkatkan diri. Model GAN akhirnya menyatu dan menghasilkan gambar yang terlihat nyata.

GAN telah berhasil diterapkan pada tensor gambar untuk membuat anime, tokoh manusia, dan bahkan karya agung van Gogh. (Untuk penggunaan modern lain dari jaringan saraf, lihat 6 Kemajuan Besar yang Dapat Anda Atribut ke Jaringan Syaraf Tiruan.)
Kesimpulan
Jadi, apakah pembelajaran mendalam hanya sekelompok jaringan saraf pada steroid? Sebagian.
Meskipun tidak dapat dipungkiri bahwa kinerja perangkat keras yang lebih cepat telah berkontribusi besar pada keberhasilan pelatihan arsitektur saraf yang lebih kompleks, multi-layer dan bahkan berulang, juga benar bahwa sejumlah unit saraf baru yang inovatif dan arsitektur telah diusulkan dalam bidang apa sekarang disebut pembelajaran dalam.
Secara khusus, kami telah mengidentifikasi lapisan konvolusional di CNN, unit LSTM, dan GAN sebagai beberapa inovasi paling berarti di bidang pemrosesan gambar, analisis deret waktu, dan pembangkitan bebas.
Satu-satunya hal yang harus dilakukan pada titik ini adalah untuk menyelam lebih dalam dan belajar lebih banyak tentang bagaimana jaringan pembelajaran yang mendalam dapat membantu kita dengan solusi baru yang kuat untuk masalah data kita sendiri.